En el ecosistema actual de operaciones globales, la diferencia entre el éxito y una crisis reputacional irreversible se mide en segundos de inactividad. Definimos como Misión Crítica a cualquier sistema cuya interrupción o falla causaría consecuencias catastróficas para las operaciones y aunque solemos asociarlo a Data Centers, este concepto es el núcleo de hospitales, el sector bancario (por el impacto económico) y servicios públicos esenciales. Una caída no solo detiene el flujo; puede causar un daño irreversible a la reputación de una marca con décadas de trayectoria.
Para las organizaciones que buscan el liderazgo, la redundancia es solo una parte de una ecuación mucho más grande: la Alta Disponibilidad (HA).
Redundancia vs. Alta Disponibilidad: ¿Cuál es la diferencia?
A menudo se confunden estos términos, pero su enfoque es distinto:
- Redundancia: es un concepto estático centrado en el hardware. Consiste en añadir componentes extra (respaldo eléctrico y de datos) para evitar que la falta de una pieza detenga el proceso. No garantiza por sí sola la actividad continua, es simplemente tener "piezas de repuesto" listas para entrar en acción.
- Alta Disponibilidad (HA): es un enfoque dinámico centrado en el servicio. Es la capacidad autónoma del sistema para poseer resiliencia automática y recuperación sin intervención humana. Mientras la redundancia es una herramienta, la HA es el objetivo estratégico para que el servicio siga funcionando pase lo que pase.
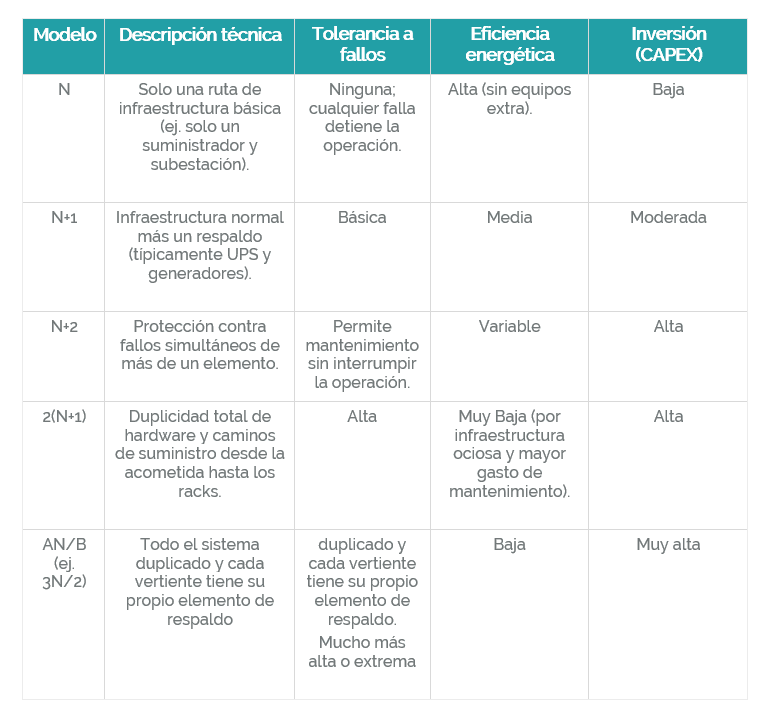
Modelos de infraestructura y su impacto en el CAPEX
La inversión en activos (CAPEX) varía drásticamente según la tolerancia al fallo y la eficiencia energética deseada como se muestra en la siguiente tabla:
Los 5 pilares de la alta disponibilidad
Para eliminar el Punto Único de Falla (Single Point of Failure), una instalación de HA debe integrar:
- Clustering: agrupar componentes para que actúen como una sola unidad operativa.
- Failover automático: conmutación instantánea al respaldo sin intervención humana, evitando los tiempos de los servomecanismos manuales.
- Self-Healing (Autocuración): capacidad de detectar y reiniciar procesos fallidos mediante modelos de Inteligencia Artificial que superan al monitoreo tradicional BMS.
- Balanceo de Carga: distribución inteligente para no sobrecargar ninguna línea de suministro.
- Monitoreo Integral: supervisión de hardware, servicios, latencia (retraso de datos) e integridad de datos (replicación síncrona).
La Regla de los "Nueves" y la Misión Crítica
La disponibilidad se mide por el tiempo de inactividad (Downtime) permitido al año:
- 99% (Básico): implica 3.65 días de caída anual.
- 99.999% (Idóneo): conocido como los "5 nueves", permite solo 5.26 minutos de inactividad al año.
- 99.9999% (Extremo): solo 31.5 segundos al año; aplicado en seguridad nacional y urgencias médicas.
Un dato alarmante: el 70% del tiempo de inactividad (downtime) en instalaciones de misión crítica es causado por error humano. Por ello, la HA busca automatizar procesos para mitigar este riesgo, además de proteger contra fallas de infraestructura (20%) y ciberataques (10%).
Métricas de Resiliencia: MTBF, MTTR, RTO y RPO
Para evaluar la disponibilidad se utilizan fórmulas basadas en el tiempo:
- MTBF (Mean Time Between Failures): Tiempo medio entre fallos (buscamos maximizarlo).
- MTTR (Mean Time To Repair): Tiempo medio de reparación (buscamos minimizarlo).
- RTO (Recovery Time Objective): Tiempo máximo para restaurar el servicio. En HA, el target es cercano a cero segundos.
- RPO (Recovery Point Objective): Punto máximo de pérdida de datos tolerable; la meta es una replicación síncrona e íntegra.
Mientras la redundancia representa un costo necesario en hardware, la alta disponibilidad constituye una inversión estratégica en continuidad operativa, protección del servicio y reducción del riesgo de downtime.
Para alcanzar niveles de resiliencia Tier III o Tier IV, no basta con duplicar equipos. Se requiere una arquitectura capaz de permitir mantenimiento concurrente, es decir, intervenir, reparar o sustituir componentes críticos sin apagar los servicios esenciales.
En KINENERGY desarrollamos soluciones de infraestructura crítica alineadas con marcos internacionales de referencia, como:
- Uptime Institute, para criterios de certificación Tier.
- ANSI/TIA-942, para infraestructura de centros de datos.
- ISO 22301, para continuidad de negocio.
Si tu organización está desarrollando un data center, edificio crítico o sistema que no puede detenerse, podemos ayudarte a evaluar, diseñar y optimizar su resiliencia operativa.
Solicita una consultoría técnica enhola@kin.energy o déjanos tus datos.

Saúl Santana
Coach de Desarrollo Técnico
Coach de Desarrollo Técnico

{kind=link}